Initial Request
The client monitored 80–120 chronic patients per clinician and needed a system to become clinically actionable so that it surfaced clinical risk automatically without adding review time.
Their concern was not collecting more patient data; clinicians were already receiving SpO₂, weight, respiratory rate, and activity data from multiple devices.
The desired outcome was a platform that would help detect a patient’s deterioration and guide clinicians to know where to focus their efforts.
Project Background
Client: Intelligent Chronic Care Hub — a mid-sized digital health company running RPM programs. The number of data gathered did not benefit the quality of care and the organization had reached a saturation point. Timing was critical as clinicians were managing many patients and manual review was no longer feasible.
Clinicians reviewed patients manually, in no particular order. Deterioration was found late. That admission started this engagement.
Core Challenges
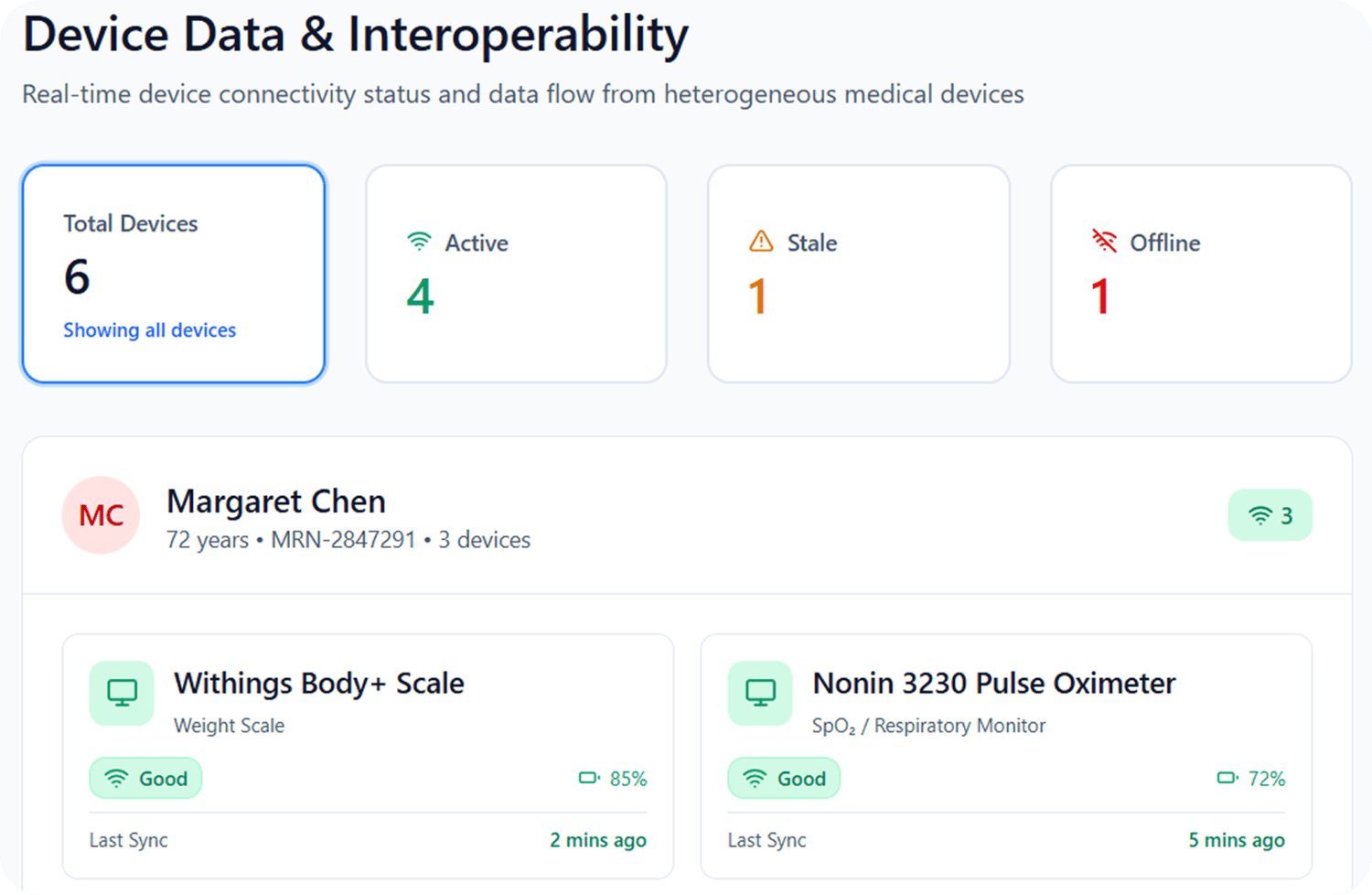
The client was looking for a revamped dashboard. There were four issues discovered in the structure, all of which made the others more serious.
When the COPD patient’s condition actually deteriorated, the alert looked identical to the 47 false alarms that had occurred earlier that week.
ALERT FATIGUE is created through generic thresholds. A COPD patient with a baseline SpO₂ of 88% was flagged daily. Clinicians stopped trusting the system. When a real event occurred, the alert looked like every false one before it.
No signal correlation. Decompensation Pattern: Weight up, SpO₂ down, activity dropping. Arriving from separate devices in isolation, each reading looked unremarkable. Nothing connected them.
Detection had nowhere to go. Follow-up ran by email and verbal handoff. No assignment, no audit trail, no way for another clinician to pick up a thread mid-shift.
Device offline looked like clinical deterioration. A flatline on screen could mean either. Both were indistinguishable.

Process
Three structural decisions shaped the architecture. Each was chosen over a viable alternative for a specific reason.
Multi-signal correlation instead of more complex threshold rules.
Raising the complexity of individual thresholds would not have solved the core problem. Decompensation does not present as a single metric crossing a line but as a pattern across metrics over time. Weight rising, SpO₂ falling, and activity declining are each unremarkable in isolation. The correlation engine was chosen because it detects compound events, not because individual signal logic was inadequate.
Patient-level overrides instead of individual protocols.
A per-patient protocol would require clinical configuration for every patient from scratch. The chosen approach uses organisation-wide defaults as a starting point and allows clinicians to override specific thresholds within a patient’s profile. This keeps the system manageable at scale while still accommodating patients whose baselines fall outside population norms.
Incident workflow instead of data dashboards.
Detection without follow-through has no clinical value. A dashboard that surfaces a risk but provides no mechanism for assignment, tracking, or handoff still leaves the outcome dependent on whoever happened to be looking. The incident workflow was chosen because it closes the loop from detection to assigned action to documented resolution.
Working on Something Similar?
Get Free ConsultationProcess
In practice, there were 5 process phases with each one being a prerequisite for the next.
Phase 1: Signal audit
Every data stream mapped before any architecture was proposed. Two signals had inconsistent timestamps that would have broken correlation logic — fixed at the data layer first.
Phase 2: Correlation engine
Multi-signal groups replace individual metric alerts. Time-window logic correlates signals within clinically relevant intervals — not just simultaneously.
Phase 3: Patient-specific rules
Organization-wide defaults plus patient-level overrides. The COPD patient at 88% baseline gets a threshold built around their normal, not the population average.
Phase 4: Triage dashboard + incident workflow
Patients sorted by risk level automatically. One click creates a structured incident: summary generated, clinician assigned, status tracked through to resolution.
Phase 5: Device status layer
Every data gap labelled: “No data received — device not transmitting.” Active, stale, offline shown separately. Clinical event vs. operational failure, distinguishable before acting.
Business Outcomes
Evaluation based on internal operational measurement. Results should be interpreted as observed outcomes within the deployment environment.
Time
Median time to identify and queue high-priority patients dropped from roughly 15–20 minutes of manual review to under 2 minutes.
False-Alert
Observed false-alert frequency decreased from approximately 65% to 12% after introducing: patient-specific thresholds multi-signal correlation separation of device-status issues from clinical events.

Higher Clinician Operating Capacity
Clinicians reviewed 50–100 monitored patients per triage session without manual prioritization.
Device Transmission Interruptions
Device transmission interruptions were operationally distinguished from clinical deterioration, reducing unnecessary escalation.
Verbal Handoff Replaced by Structured Incident Workflow
One click generates a clinical summary, assigns a clinician, and opens an auditable thread — visible across the full care team until resolved.

Empeek’s Team Reduces Time to Market by 15%. Start Your Project Today.
Schedule a CallOur Custom Healthcare Software Development Services
FAQs
We already have alert fatigue. Won't this make it worse?
Generic thresholds are replaced with patient-specific ones. For a COPD patient with a baseline of 88%, the system stops treating that as an alert condition. Alert volume decreases while signal quality improves.
Do device data gaps trigger false alerts?
No. Every gap is labelled: “Device not transmitting”
Operational issues are resolved through device management, which eliminates unnecessary clinical escalation.
Can clinical teams configure alert logic without developer support?
Yes. Thresholds and multi-signal rules are configured directly in the Rules Engine. Patient-level overrides are set by responsible clinicians within the patient profile.
What if the assigned clinician is unavailable when a high-risk patient is flagged?
Every incident remains visible across the care team through status tracking — Open, In Progress, Resolved. The audit trail stays with the incident rather than an individual.


![Revive Telehealth: Scalable Platform for Behavioral Health [Case Study]](https://empeek.com/wp-content/uploads/2024/09/revive.jpg)
![Real-Time Health Monitoring System Using IoT [Case Study]](https://empeek.com/wp-content/uploads/2024/09/biobeat.jpg)